It’s good to be busy! I’ve spent the first quarter of 2024 sinking my teeth into a few exciting projects. Being fully booked is great for business, but not for blogging! Now that the dust has settled, I finally have some quiet time to document the highlights of the past three months.
The project I’m about to discuss took me back to my software developer roots in the healthcare industry, but also challenged me to upskill in short order.
The situation
Aretetic Solutions approached me in February with a dilemma. They were providing support and services to a healthcare tech platform whose main clients were groups serving people with rare diseases. The groups could create and administer surveys to their members in order to collect both demographic and healthcare information, which could then be accessed, with proper consent and approval, by researchers trying to learn more or develop treatments for these diseases. Unfortunately, the company behind the platform went bankrupt. Per their terms, after just 30 days they were allowed to delete all the data, permanently. This would obviously have a major impact on the groups and the members they serve.
Aretetic approached me seeking a full-stack developer who could stand up a secure, GDPR-compliant cloud database to house the survey data, and also help with the migration of the data from the old platform.
The pitch
In true programmer fashion, I’m going to copy-paste the introduction section of my proposal document, because it will save me some typing, and because it does an excellent job summarizing my proposal to Aretetic.
In the world of modern healthcare, secure tools to manage patients’ personal health information are essential. The challenge for many healthcare tech projects is striking the right balance between security, accessibility, and cost effectiveness. Patients, and everyone supporting their care, need information to be up-to-date and readily accessible, yet protected from any sort of unauthorized access. These kinds of systems can be expensive to build, but costs can be managed through judicious prioritization of the most important features.
I will deploy a relational database in a HIPAA-compliant cloud environment that can store health and demographic information for the patients your organization serves. This database will live inside a private cloud network, cut off from the public internet. Access to the database will be restricted by role-based user access policies implemented inside the cloud provider console, as well as a VPN gateway or bastion host for developer access.
In future projects, you could invest in additional features, such as an API gateway and web interface that would allow users to log in and edit their own PHI.
My proposal also broke down the key components of the new system architecture. There were:
- The relational database
- The “virtual private cloud,” which isolates the database from the public internet
- The secure endpoint to allow administrative access to the private cloud from the outside world
- A database backup plan, to avoid data loss in the event of a disaster
- A batch script to read files containing exported data from the old platform, and write to the new database
Finally, I identified the potential risks of the project, and my approaches to mitigating those risks. Here’s the verbatim text copied from that section:
Legal compliance. The transmission and storage of personal health information (PHI) is subject to a host of laws and regulations. I will take note of any regulations you identify to me, adhere to them myself during development, and contact the cloud provider to confirm the compliance of any products this project uses.
Data loss. Any storage solution poses a risk of failure at any time, whether due to faulty hardware, defective software, or a cyberattack. I will work with you to establish a suitable backup and restore plan prior to development.
Unauthorized access. PHI is highly sensitive information. Improper access can cause serious harm to the subject and others. I will apply a zero-trust security policy to the performance of this project, which involves granting the minimal required authorizations requested by anyone who needs access to the system, or the data within it. It also means I will use spoofed sample data wherever possible during development and testing, to reduce my own access to real user data.
Liability. In spite of my commitment to due diligence, I am not immune to mistakes. I carry general and professional liability to protect myself and my clients from damages caused by errors and omissions in my work.
Project risk. Every software development project is subject to time and budget constraints. I cannot guarantee project completion by a certain date. However, I offer fixed quote pricing, and will continue working beyond the estimated completion date at no additional client cost. I can also prioritize projects on a tight deadline for an additional percentage fee.
Project highlights
Here are several highlights from my work. As always, I’ve focused on my approach and decision making over specific technical minutia.
Locking down the virtual network
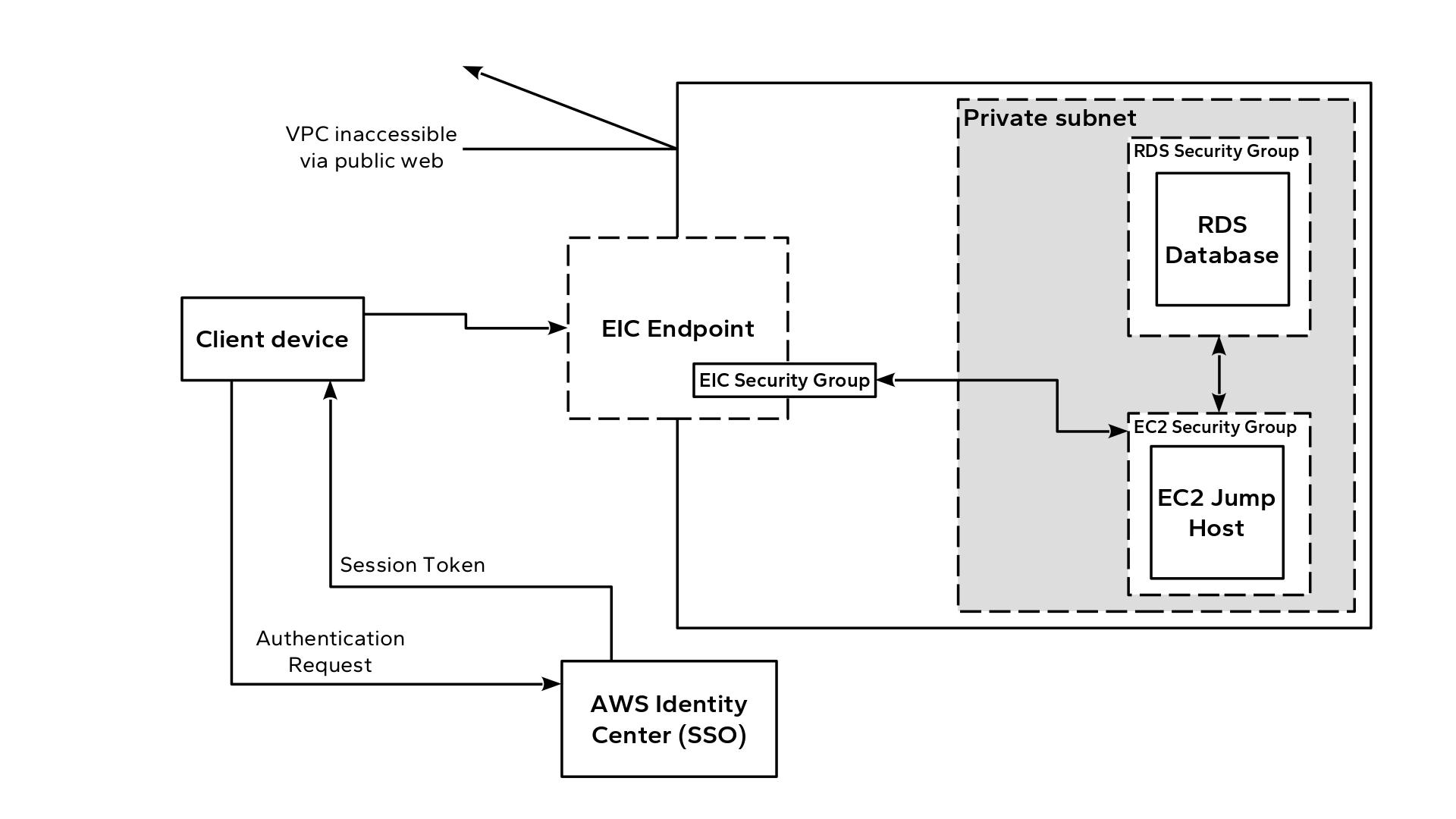
This was a top priority of mine, and one of the most time-consuming aspects of the job due to my relative inexperience with the AWS ecosystem. I knew I needed to deploy the database in a Virtual Private Cloud (VPC), to protect it from brute-force attacks and other exploits my malicious actors on the public internet. But I also knew that the Aretetic administrator, working from a computer outside the VPC, needs to connect to the database and run the migration script. After extensive research, I identified three potential solutions:
- A “bastion host,” a server inside the VPC yet publicly accessible, with SSH capabilities. Only users with SSH public keys loaded onto the bastion host can connect to it. Once connected, users can utilize ssh port-forwarding to access select private resources within the VPC. Rules defined in the AWS security groups regulate the resources the bastion host can access.
- A “virtual private network” (VPN) connection. Users install a client such as OpenVPN, then establish a connection to the VPN server, which lives inside the VPC but is exposed via an internet gateway, similar to the bastion host. Once a connection is established, the user’s device is effectively “inside” the VPN and can access all resources.
- A newer AWS feature called an EC2 Instance Connect Endpoint (EIC Endpoint). This is also known as an “identity-aware proxy.” Like a bastion host or VPN server, the EIC endpoint acts as a bridge between the VPC and outside world. However, the EIC endpoint does not accept basic HTTP or SSH requests. Instead, a user authenticates with an identity provider configured inside the AWS account, and receives an access token in return. This token is passed to the EIC endpoint. If the user passes a valid token, and has the appropriate IAM authorization to connect via EIC Endpoint, the endpoint creates a temporary public key pair that enables the user to connect to the EC2 host via SSH for the duration of the session.
Each solution had pros and cons. The bastion host is easy to setup, but requires an experienced administrator to lock down properly. Even more work is required to audit user sessions, and to periodically expire credentials via public key rotation. The VPN connection is convenient, but in addition to similar limitations regarding user audits and credential duration, it also does not allow fine-grained control of access to resources inside the VPC. The EIC endpoint turned out to be the best option. It permits a zero-trust approach via integration with AWS IAM roles and temporary access credentials, and it does not require any VPC gateway to the public internet.
Setting up this solution turned out to be an ordeal, mostly due to human error. Six hours and one mistyped IP address later, the EIC endpoint was working!
Do you want a tech blog post explaining how to set this up? Let me know!
Modeling data for backwards compatibility and future flexibility
I’ve been working with relational databases and the SQL language for the entirety of my developer career. This project was a landmark, however, as my first opportunity to model and implement the entire schema of a database. The requirements posed two challenges that proved to be somewhat at odds. On the one hand, the database needed to accomodate the legacy data from the old platform. On the other, no one actually liked the schema of the old system, and would likely want to change how things work in the future.
To tackle these conflicting requirements, I constructed a schema comprised of three key tables:
- The “Member” table represents a user who may respond to surveys.
- The “Survey” table represents a single survey that members may respond to.
- The “Response” table represents a single occurrence of a user responding to a survey, at a moment in time. A single user might respond to a survey multiple times if their answers to the questions have changed.
To accomodate the legacy data, I added a two accessory tables. Each row in the first table created a one-to-one relationship between a “participant identifier” from the legacy platform and the id of a general “Member.” Each row in the second table represented a single survey question and corresponding user answer, which included a foreign key to a single “Response” row. By doing this, Aretetic could import the legacy data as soon as possible, without locking themselves into any specific database structure for storing future survey questions and answers.
The real value of a relational database is its ability to enforce data integrity. Using carefully defined constraints and triggers, I added some useful features to the schema. For example, a survey cannot be accidentally deleted if it has linked responses; an admin would need to intentionally delete all responses in the database before deleting the survey. Additionally, if a “Member” row is deleted, all “Response” rows linked to that member are also deleted (which also cascades to individual question-answer rows). This helps Aretetic accomodate GDPR requests from users to delete their data. Of course, a routine database backup plan provides a recovery path in case a user is deleted erroneously.
Automation infrastructure deployment
When I’m deploying code and infrastructure for a client, it’s important that my steps are easily replicable. This isn’t just for my own benefit, either. As I’ve written before, I strongly oppose vendor lock-in as a customer, and I apply that same philosophy to my own clients. If they decide to hire different developers in the future, I want those contributors to have everything they need to support the platform.
I created a pair of Terraform modules to automate deployment and configuration of the AWS infrastructure, which I’ve pushed to the client’s repository. The tooling certainly saved me time, especially while debugging issues with networking configurations. But more importantly, even future contributors who are unfamiliar with Terraform or choose to deploy manually can read my Terraform configuration files as a blueprint documenting the way I set things up.
Scripting the data migration
At first, I assumed the import process could be done manually with SQL client and a few insert statements. My stance flipped when I learned the volume of data: 50+ files with hundreds of responses per file. The export also split each survey into two files: a plain CSV containing the survey metadata, and a password-protected Excel spreadsheet containing the actual responses. The CSV file was formatted strangely, with the first 7 columns representing survey-level data (populated only on row 1), while the remaining columns contained question-level data (populated on many rows). The Excel data wasn’t much better: Each row was a single response, which was fine. The first column was the participant identifier. After that, every column header contained the full text of the question, with users’ answers in the cells below. Every survey response file had a different number of columns.
Suffice to say, automation was necessary.
Since the Aretetic admin would be running the migration, I needed to write the script in a runtime environment familiar to them. Fortunately, we both knew some Python. In addition to ease of use, Python’s power comes from it’s incredible standard library and third-party package repository. Before and while writing the migration script, I carefully curated a list of well-maintained package dependencies. Shoutout to the maintainers of the following packages for saving me countless hours’ worth of work:
petl: This data pipeline library was really easy to work with, even for someone with zero big data experience. It made extracting, transforming, and loading the data a snap.openpyxl: This library integrates with petl to load Excel spreadsheets into memory.msoffcrypto-tool: This nifty library can unlock password-protected spreadsheets, which can then be fed into openpyxl.psycopg: The wonderful PostgreSQL python driver.
Fortunately, I managed to provide the admin a pretty solid user experience, as far as CLI scripts go. They only needed to pass the script the paths of the two export files for the survey, as well as the survey’s name to store in the database. Then, they’d be prompted for the password to unlock the XLSX file. The script included rudimentary data validation that would report an error if something looked wrong. And, it was idempotent, meaning they could safely re-run it after a failure without worrying about duplicating data. This last point proved particularly useful when the 1-hour session limit for EIC Endpoint connections would expire in the middle of a migration (a distinct downside of the EIC Endpoint strategy).
Areas of improvement: avoiding waterfall development
If there’s one thing I wish I could do over on this project, it would be requirements gathering. The initial sample data I received was only half of the data I needed (the responses, not the survey metadata). Additionally, I didn’t inquire about the volume of data until late into the project. This resulted in some painful pivots, including a partial revision of the database schema, and a couple late night crunch sessions writing a migration script far more complex than I had planned. More frequent check-ins with my point of contact could have exposed my false assumptions earlier in the process, saving me time and effort. As a former Scrum Master and Tech Lead, I ought to know that!
Final takewaway
This project was both fulfilling and a great boost in confidence! I’m glad I could help Aretetic, as well as everyone who depends on the data we salvaged. At the same time, I proved to myself that my versatility and adaptability extends beyond development into the world of cloud infrastructure, software architecture, and database design. I’m looking forward to partnering with Aretetic in the future to help them extend the functionality and features of their new platform!
Need an experienced developer to deliver innovative cloud solutions? Contact me today so we can schedule your free consultation.