In this client story, I collaborate with a startup founder, taking some back-end development work of their hands. In the process, I get my first exposure to the Google Cloud Platform ecosystem, and do a tiny bit of performance engineering to accomodate the rather strict rate limit of an external API.
The situation
Every Voice is a B-corporation headquartered in Brooklyn, New York. They are developing mobile apps for iOS and Android that are, in their own words, “empowering transparency in democracy.” The apps allow constituents to share demographics, vote on polls, and sign petitions, without the need for emails, text or phone calls. Representatives at the federal, state, and local levels can then use aggregated information to inform their decision-making. The app also serves as a hub of information about representatives, upcoming legislation, and more.
With the 2024 U.S. general elections fast approaching, the small team is spread thin trying to get everything ready for launch. One of the founders reached out to me through a referral from a mutual contact. They needed a developer to build an ETL pipeline that would periodically fetch the latest bill updates from the Congress.gov API and load them into their NoSQL database. Delegating this work would free up the rest of the team to focus on other aspects of the app, such as the user experience.
The pitch
Jackson, the founder who acted as my point of contact throughout this project, had already documented a pipeline architecture in a Confluence wiki page. For the most part, my pitch mirrored this proposed technical design. However, I knew I could bring more value to this project that just following instructions. In my proposal, I identified several challenges which surfaced during my preliminary research into Google Cloud and the Congress.gov API. Here they are, straight from the proposal document:
- A standard Congress.gov API key is limited to 1,000 requests per hour. The endpoints for fetching bill batches by date range only return a fraction of the information available for each bill, and impose a pagination limit of 250 bills per request. Fetching full information for a bill will require several more calls for each bill: one to the single bill resource endpoint, and one more for each desired sub-resource (bill text, amendments, etc.). The pipeline should be built to work around these limitations with minimal sacrifices.
- Any part of the pipeline may fail during a run, including a request to extract bill data, or an attempt to write to the database. The pipeline should log, and possibly alert, all failures, and implement a suitable retry mechanism to minimize manual intervention.
- The pipeline should be idempotent, meaning that subsequent requests to process bills for the same date range should result in the same final state of the database documents (presuming the source data has not changed). The pipeline should not produce duplicate documents of the same bill in the database.
- The pipeline needs to perform well at scale, which depends on the span of the date ranges requested in a single run, and by the number of bills last updated within that range. Load testing will be important to verify the feasibility of the solution.
- To provide future project contributors an optimal experience, the pipeline should be well-documented. The documentation + the source code for cloud functions should be stored in a cloud repository owned by Every Voice.
As with other projects, I highlighted four potential risks up-front, along with mitigation strategies:
Work done outside developer’s area of expertise. While I have Python experience, Python data pipelines are not my specific area of expertise. To that end, I’ll consult with you closely as I work, and research best practices as needed.
Excessive spending on cloud services. Google Cloud is a powerful cloud platform, but it’s easy to build expensive solutions if you aren’t careful. I am aware of this risk and will factor cloud pricing costs into any solution I build by leveraging Google’s pricing calculator tools. I’ll try to provide an accurate estimate of the cost to run the pipeline at the end of the project.
Poor pipeline performance. Software solutions are only worthwhile if they can solve a problem at the necessary scale. I’ve identified the primary scaling factors to be the size of the requested date range and, more specifically, the number of bills included in that range. I’ll test the pipeline with large ranges and large sets of bills to determine the performance.
Dissatisfaction with progress. Despite my best efforts, you may be dissatisfied with my progress and wish to terminate the project. I offer all new clients a no-hassle cancellation policy so you don’t feel trapped in a contract.
Project highlights
The highlights I’ve chosen from this project demonstrate the growth and maturity I’ve gained as a developer compared to my first years in the industry. My clients can expect a holistic, big-picture approach to software development that considers important factors such as error recovery and performance, without overcomplicating the solution.
Do one thing, and do it well
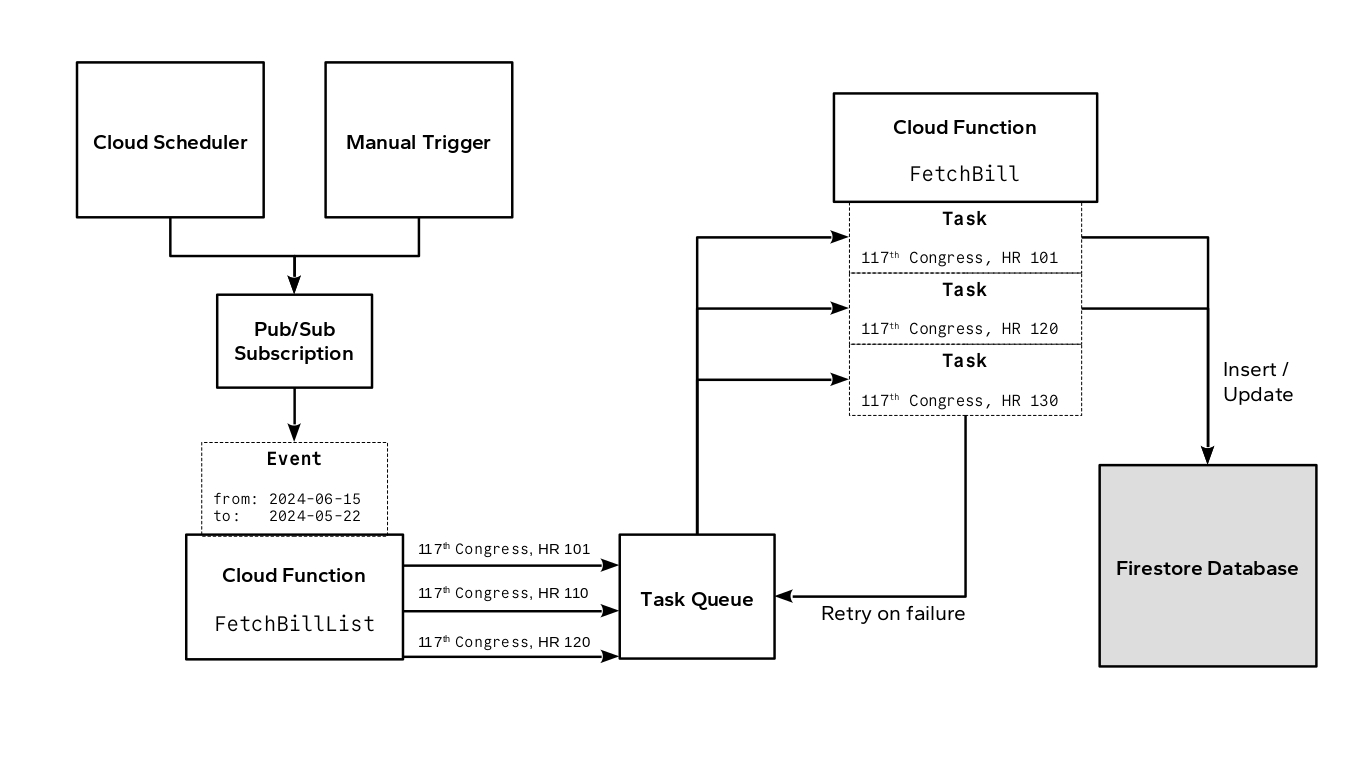
My approach to this solution embraced that timeless kernel (hehe) of Unix wisdom: “do one thing, and do it well.” The original design of the system consisted of three main parts:
- A “Pub/Sub” event topic which triggers…
- A Cloud Function which fetches bill data, transforms the data, and loads it into…
- A Firestore database
I proposed one key change: splitting the Cloud Function into two functions, intermediated by a Cloud Tasks queue. The first function executes once per pipeline event to fetch the list of recently added/updated bills. The second executes once per bill to fetch bill-specific data and commit it to the database. Between these two functions sits the Cloud Tasks queue which provides important auxiliary features such as automatic retries and rate limiting.
Thanks to this modification, each function implementation remained relatively lean and easy to comprehend, since it had only one “job” to do.
Optimizing for rate limits
As called out in my proposal, the biggest bottleneck in terms of performance was the 1,000 requests-per-hour rate limit imposed by the Congress.gov API. The API’s design amplified this problem. For one thing, the API resource for fetching a list of bills returned at most 250 per request, and only returned basic information about a bill. To get the list of bill cosponsors, the bill’s full text URL, and other key properties required five separate requests for each bill! As a consequence, our pipeline could process, at the very most, 200 bills per hour. If we exceeded that limit, we’d receive a 429 error, and too many violations could result in the revocation of API access.
Fortunately, Every Voice planned to run the pipeline once per week. Fortunately for us, the historic bill counts over weekly date ranges rarely exceeded 1,000 bills, so a pipeline run could load all bills in a few hours, IF the pipeline was properly configured. To do that, I needed a little math:
1,000 req per hour / 5 req per task
= 200 tasks per hr
200 tasks per hr / (3600 sec per hr)
~ 0.055555555 tasks per sec
round down to 0.055 tasks per sec
= 3.3 tasks per min
= 198 tasks per hr
~ 18.18 sec per task
Setting our queue’s max dispatch rate to 0.055 establishes an upper limit of 198 tasks dispatched per hour. That is pretty close to our theoretical maximum of 200.
Another important rate of concern was the rate that we enqueue tasks onto our queue. Unlike when we dispatch tasks from the queue, we aren’t worried about the Congress.gov API’s rate limit. Since we can fetch 250 bills per request, we’ll only need a half-dozen requests. However, if we try adding all of those tasks to our queue as fast as possible, we could overwhelm the system.
Google provides guidance for managing scaling risks , which I’ll summarize here:
- Enqueue no more than 500 tasks per second for the first 5 minutes
- Increase that rate by no more than 50% every subsequent five minutes
- Keep combined task operations (enqueue + dispatch) under 1000 per second to avoid latency increases
To control the task creation rate, I implemented a rudimentary throttling behaviour in the Cloud Function. The algorithm follows these steps:
- Initialize a variable called
batch_sizeto the value500. - Initialize a variable to track our time elapsed.
- Loop through our first 500 fetched bill, creating a task for each one and updating time elapsed.
- After every 50 tasks created, compare the time elapsed to our maximum rate limit of 500 tasks per second.
- If the rate has exceeded our limit, sleep for just long enough to bring our actual rate down to the maximum.
- When a batch completed, check if five minutes has elapsed since the last change to
batch_size. If so, increasebatch_sizeby 50%, up to a maximum of1000.
An example probably helps here. If we’ve created 250 tasks out of a batch of 500, we need at least 500 milliseconds (0.5 seconds) to elapse, since our maximum rate is 500 tasks per second and we’ve created half of our batch so far. If we find that only 300 milliseconds (0.3 seconds) have elapsed, we throttle our process for 200 ms in order to achieve an acceptable rate.
Areas of improvement: Logging and monitoring
This is a longstanding gap in my developer expertise that I really need to invest in soon. Console logs and print statements help with local development debugging, but critical cloud applications require detailed, methodical logging and alerting. My limited knowledge of Google Cloud’s logging and auditing capabilities left me combing through slow, cluttered, verbose log feeds. This could be avoided if I had a better understanding of how to capture and filter the signals from within the noise.
Final takewaway
I enjoyed every aspect of this project, including the opportunity to dip my toes into the Google Cloud ecosystem. I’m grateful to Every Voice for reaching out and trusting me with a critical aspect of their infrastructure, and I hope to work with them again in the future!
Need an experienced developer to deliver innovative cloud solutions? Contact me today so we can schedule your free consultation.